
Abstract
Although few of us design general-purpose programming languages,
experienced programmers regularly design Domain-Specific Programming Languages
(DSLs) for specialized domains like
telecommunications, avionics, graphics, text processing, databases,
bioinformatics, gaming, and so on.
Language design should follow a methodology, just like software development does. But language-design based on denotational semantics or structural operational semantics has failed --- the techniques are too formal and artificial.
This talk shows how to use namespaces (dictionaries) as the main semantic concept for designing, explaining, and implementing a programming language. Combined with Strachey's suggestions for application-domain selection and Tennent's language-extension principles, we obtain a semantics methodology that is a practical alternative to formal semantics.
In the talk, the methodology is applied to a simple example to explore the choices available to a DSL designer.
It is unlikely you will use denotational
semantics or structural operational semantics to design your language.
(But I must admit, I like Scott-Strachey denotational semantics!)
Why are these semantics methods little used ?
There is a huge gap between the semantics metalanguage (lambda-calculus, inference-rule sets, etc.) and the implementation (storage layout, data structures, etc.). Surely, we can do better.
A language design should include
The purpose of C is to manipulate the runtime machine in this picture.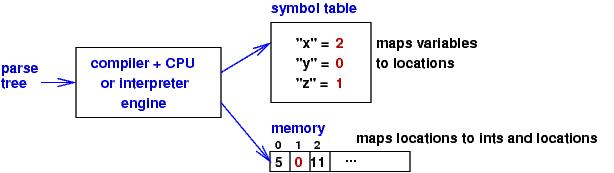
We must express in syntax the domains and operations of the runtime machine:
===================================================
C : Command L : LefthandSide
E : Expression I : Identifier
D : Declaration N : Numeral
C ::= L = E | C1 ; C2 | while ( E ) { C } | if ( E ) { C1 } else { C2 }
E ::= N | ( E1 + E2 ) | L | & L
L ::= I | * L
N ::= string of digits
I ::= strings of alphanumerics
===================================================
Assignment, =, manipulates memory, and
operators, * and &, compute on locations.
Symbol-table use happens within identifiers, I.
The syntax defines C's expressible values to be ints and locations.
The program that created the above storage configuration was
this one:
y = 5 ;
z = &y ; # store in z's cell the location named by y
x = (6 + *z) # add 6 to the int stored where z points and assign
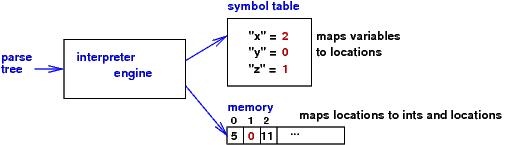
We might express in the syntax the symbol table and memory themselves. Indeed, C lets you express approximations of both --- a struct is a C-coded "baby symbol table", and an array is a C-coded "baby memory". (We won't develop them here....)
Now, we can enrich the syntax with naming devices --- declarations (or if you are Bjarne Stroustrup, lots more!).
let d = {'x'=2}
d['y'] = d['x'] + 1
lock d
d['x'] = 1
defines namespace, d == {'x'=1,'y'=3}, to which no more names can be added.
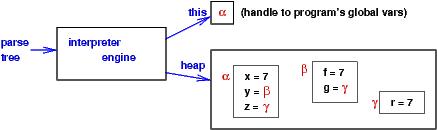
Namespaces appear in semantic models as
|
|
The namespaces are labelled by Greek letters; the values assigned to the fieldnames are denotable values. Here, both ints and handles (namespace-addresses) are denotable values. (The notion of ``storable value'' is unneeded here.)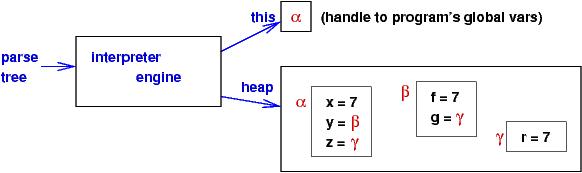
There is a distinguished handle, named this, which is the
handle to the "active namespace" whose bindings are visible to the interpreter
while it interprets commands.
===================================================
C : Command L : LefthandSide
E : Expression I : Variable
F : FieldName N : Numeral
C ::= L = E | if E : C1 else C2 | while E : C | C1 ; C2
E ::= N | ( E1 + E2 ) | L | new { F }
F ::= I | I , F
L ::= I | L . I | this
N ::= string of digits
I ::= strings of letters, not including keywords
===================================================
Here is a sample program that generates the earlier diagram:
x = 7;
y = new {f, g};
y.f = x;
y.g = new {r};
z = y.g;
z.r = y.f;
|
|
The syntax for new namespaces (new{I1,I2,...}) is inadequate;
here is one that lets us initialize the new namespace:
E ::= . . . | new { C }
Now, a (compound) command computes bindings that fill a newly
allocated namespace.
Here is an example:
x = 7;
y = new { f = super.x;
g = new {} // (*)
};
z = y.g;
z.r = y.f
The fieldname, super, gives access to nonlocal variables.
Here is a snapshot of the execution at (*), just before
the handle of the newly initialized namespace is assigned to y:
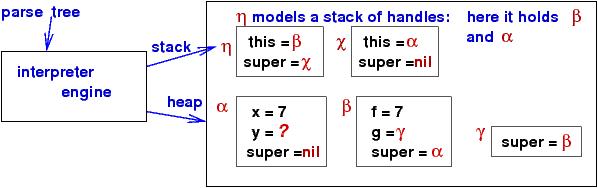
To implement new{C}, there must be a stack (or list) of handles (an activation stack) of the active namespaces. In the diagram, the stack is a linked list of dictionaries with fields this (the "top"/"head") and super (the "rest"/"tail"). The semantics of new{C} goes:
Our proposed new{C} generates
scoping conflicts, e.g.,
x = 7;
y = new {z = x; x = 0}
Does x = 0 reset global x or create a local x in y's namespace?
The situation can be disambiguated in multiple ways; we choose
a new keyword, var:
var x = 7;
var y = new {var z = x; x = 0}
where var I = E demands that E is evaluated to e and I=e
is a (new) binding in the active namespace.
Contrast the above to
var x = 7;
var y = new {var z = x; var x = 0}
where a local x is created.
Indeed, var I = E is just an abbreviation ---
``syntactic sugar'' --- for this.I = E, e.g.,
this.x = 7;
this.y = new {this.z = x; x = 0}
Again, var I = E means to bind I to E's value in the active namespace. In contrast, I = E locates the L-value for an already existing I along the chain of super links (the "static chain") and updates I at the nearest namespace where I already exists.
We are a short step from functions, classes, and methods --- we will apply Tennent's naming conventions to derive these from the core syntax. This is coming.
===================================================
P : Program
C : Command E : Expression
T : Template L : Lefthandside
P ::= T
C ::= var I = E | L = E | C1 ; C2 | while E : C end
E ::= N | ( E1 + E2 ) | L | new T
T ::= { C }
L ::= I | L . I | this | super
===================================================
we define this semantics:
===================================================
Storage structure:
heap : Dictionary of { Handle : Namespace }
// has an operation, allocateNS(d), where the bindings in d
// are copied into a newly allocated namespace in heap and
// the handle to the new namespace is returned
actstack : Handle
// is the handle to the front of a linked list of {'this', 'super'}
// cells in the heap (the dynamic chain of activation records).
// There are the expected push, pop, top operations.
where Namespace = Dictionary of { Identifier : Denotable }
Denotable = Handle | Int
LValue = (Handle , Identifier)
and Handle is the set of namespace addresses and Int is the set of integers
Program[[.]] updates heap:
[[ T ]] = Template[[ T ]]
Command[[.]] updates heap:
[[ var I = E ]] == heap[top()][I] = Expression[[ E ]]
[[ L = E ]] == let (han,id) = Lefthandside[[ L ]]
heap[han][id] = Expression[[ E ]]
[[ while E : C end ]] == while Expression[[ E ]] != 0 :
Command[[ C ]]
[[ C1 ; C2 ]] == Command[[ C1 ]]
Command[[ C2 ]]
Expression[[.]] updates heap and returns Denotable:
[[ N ]] == return int(N)
[[ E1 + E2 ]] == let n1 = Expression[[ E1 ]]
let n2 = Expression[[ E2 ]]
return add(n1, n2)
[[ L ]] == let (han,id) = Lefthandside[[ L ]]
return heap[han][id]
[[ new T ]] == let han = Template[[ T ]]
lock han
return han
Template[[.]] updates heap and returns Handle:
[[ { C } ]] == let newhandle = allocateNS({'super' = top()})
push(newhandle)
Command[[ C ]]
pop()
return newhandle
Lefthandside[[.]] returns LValue:
[[ I ]] == let han = top()
let found = False
// find the most local instance of I in the static chain:
while not found and han != nil :
if I in heap[han] : found = True
else : han = heap[han]['super']
return (han, I)
[[ L . I ]] == let (han,id) = Lefthandside[[ L ]]
let han2 = heap[han][id]
return (han2, I)
[[ this ]] == return (actstack, 'this')
[[ super ]] == return (top(), 'super')
===================================================
E ::= . . . | new T | ! EHere are the revised semantics:
Expression[[ new T ]] == return Template[[ T ]]
Expression[[ ! E ]] == let han = Expression[[ E ]]
lock han
return han
var ob = new { var f = !new {var x = 0} };
ob.g = ob.f.x;
ob = !ob
var ob = new { var f = 1 };
this = ob;
f = 2;
this = super
If desired,
we can disallow such activity by restricting the syntax of Lefthandsides:
L ::= I | this . I | super . I | L . I
===================================================
C ::= var I = E | L = E | C1 ; C2
E ::= N | ( E1 + E2 ) | L | new T
T ::= { C }
L ::= I | L . I | this
===================================================
Robert Tennent proposed these principles for adding naming constructions:
===================================================
C : Command D : Declaration
T : Template E : Expression
L : Lefthandside N : Numeral I : Variable
D ::= proc I : C | class I : T | var I = E
C ::= L = E | C1 ; C2 | D | L ( )
E ::= N | ( E1 + E2 ) | L | new T
T ::= { C } | L ( )
L ::= I | L . I | this
===================================================
proc I: C binds a closure to I,
consisting
of C and the handle to the active namespace. It is essentially
this assignment:
var I = {'code' = 'C} // where 'super' holds C's static link to its globals
An invocation, L(), extracts the closure,
pushes its super handle onto 'actstack''s stack; and interprets the code.
At conclusion, the stack is popped.
Here is an example:
class clock : { var time = 0;
proc tick : time = time + 1 end};
var j = new clock();
var k = new clock();
k.tick()
Here is a picture of the runtime model just before the call, k.tick(),
returns:
The two calls, clock(), constructed two namespaces, and k.tick() used the one named by k.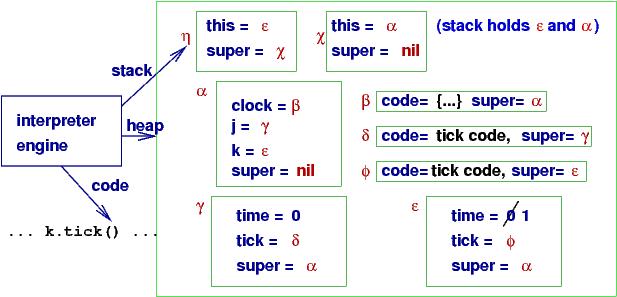
IMPORTANT: No new computational machinery is added to the model. This is the beauty in Tennent's approach --- it exploits the computational abilities already in place.
Perhaps you are thinking, ``where is the activation record for tick's call?'' We'll examine this shortly....
Here is the semantics; it is essentially identical
for both classes and procedures, but we repeat it to emphasize exactly that point:
===================================================
Declaration[[ proc I : C ]] == let active = top()
let han = allocateNS({'code' = C, 'super' = active})
lock(han)
heap[active][ I ] = han
Command[[ L() ]] == let (han,id) = Lefthandside[[ L ]]
let closure = heap[ heap[han][id] ]
push(closure['super'])
Command[[ closure['code'] ]]
pop()
Declaration[[ class I : T ]] == let active = top()
let han = allocateNS({'code' = T, 'super' = active})
lock(han)
heap[active][ I ] = han
Template[[ L() ]] == let (han,id) = Lefthandside[[ L ]]
let closure = heap[ heap[han][id] ]
push(closure['super'])
let newhan = Template[[ closure['code'] ]]
pop()
return newhan
===================================================
var time = 0; proc tock(): var m = 2; time = time + m end;will store the variables that appear local to tock (here, m) with those owned by the enclosing namespace (here, tock and time).
In any case, the question is moot once we allow parameters to
procedures --- for each call, we must allocate an activation record (namespace)
to hold the parameter-arguments bindings.
For this syntax,
===================================================
D ::= proc I1 ( I2 ) : C | class I1 ( I2 ) : T
C ::= . . . | L ( E )
T ::= . . . | L ( E )
===================================================
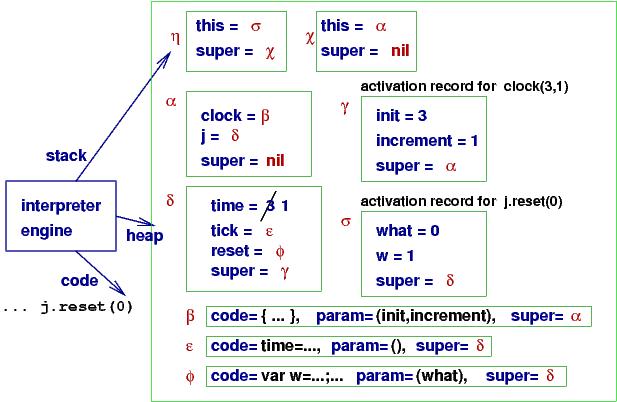
and this example,
class clock(init, increment): { var time = init;
proc tick():
time = time + increment;
proc reset(what):
var w = what + increment;
time = w }
var j = new clock(3, 1);
j.reset(0)
a snapshot of this program, just before j.reset(0) returns, looks like this:
The static chain for the call j.reset(0) is the sequence of super links
starting from σ.
Again, no new semantic machinery is required.
The semantics definition shows that an activation record is allocated
when the procedure is called with its argument:
===================================================
Declaration[[ proc I1 ( I2 ) : C ]] == let active = top()
let han = allocateNS(
{'param'= I2, 'code'= C,
'super'= active} )
lock(han)
heap[active][ I1 ] = han
Command[[ L ( E ) ]] == let (han,id) = Lefthandside[[ L ]]
let closure = heap[ heap[han][id] ]
let arg = Expression[[ E ]]
let han2 = allocateNS({'super' = closure['super'],
closure['param'] = arg})
push(han2)
Command[[ closure['code'] ]]
pop()
===================================================
For a parameterized class, class I1(I2) : T, the semantics is almost exactly the same,
where the activation record allocated at the call, new I1(E),
holds the binding, I2 = v, where v is the meaning of E.
The namespace constructed by T is linked to the activation record.
(In the diagram above, j binds to a two-namespace object,
whose "public fields" in δ link to its "private fields" in γ.)
begin D in C endThe semantics of the command block goes like this: a new namespace is allocated, into which D's bindings are placed; C uses the namespace, after which the namespace is deactivated:
For commands, the semantics looks like this:
Command[[ begin D in C end ]] == let han = allocateNS({'super' = top()})
push(han)
Declaration[[ D ]]
lock han
Command[[ C ]]
pop()
Notice the semantics prevents the block's body, C, from generating
any new bindings that might be intended for a more global namespace
than the one generated by D. This was exactly what was intended
for Algol60, Pascal, and Modula, but not for C or Java.
On the other hand, the format works well for templates:
===================================================
T ::= { C } | private D in T | L ( E )
Template[[ private D in T ]] == let han = allocateNS({'super' = top()})
push(han)
Declaration[[ D ]]
lock han
let han2 = Template[[ T ]]
pop()
return han2
===================================================
No new semantic machinery is required.
Other phrase forms can use blocks, but
modern languages often marry blocks
to parameterized abstracts, so that the private declarations
are treated like extra parameter bindings. This approach works
fine for straightforward examples, like this one:
class clock(init, increment) private var time = init :
{ proc tick(): time = time + increment end;
proc reset(what): time = what end
}
An activation, like var c = new clock(0,2),
would construct a two-namespace object, where one namespace
holds init = 0, increment = 2,
and time = 0, and another holds the handles to the closures named by
tick and reset.
The example establishes a correspondence to this code fragment,
which uses a template-block:
var c = new private var init = 0; var increment = 2; var time = init
in { proc tick(): time = time + increment end;
proc reset(what): time = what end
}
Tennent remarked there should be a ``correspondence principle''
in the semantics between declaration and parameter binding --- the semantical
effects should be the same.
It is easy to modify the semantics of parameterized abstracts to store private declarations: For the format, class I1 (I2) private D : T, the semantics of the class declaration is to store within a closure all of I2, D, and T. The semantics of the class's call, L(E), is to locate the closure named by L's L-value, allocate a new namespace, insert into it I2 bound to E's value, push the namespace, evaluate D (its bindings will be deposited into the new namespace), and then evaluate T. At conclusion, the namespace is popped.
D ::= private var I = E | private proc I1 ( I2 ) : C end | ...A private declaration cannot be indexed from outside its own namespace, that is, L.I dot-notation cannot be used to locate it. Here is the semantics of declaration:
===================================================
Declaration[[ private var I = E ]] == heap[top()][I] = Expression[[ E ]]
markPrivate(top(), I)
Declaration[[ private proc I1 ( I2 ) : C ]] == let active = top()
let han = allocateNS(
{'param'= I2, 'code'= C,
'super'= active} )
lock(han)
heap[active][ I1 ] = han
markPrivate(active, I1)
===================================================
An extra action, markPrivate(h,i), makes
L-value (h,i) private.
External (dot) indexing cannot locate a private L-value:
===================================================
Lefthandside[[ L . I ]] == let (han,id) = Lefthandside[[ L ]]
let han2 = heap[han][id]
if not isPrivate(han2, I): return (han2, I)
else : return (nil, I)
===================================================
where isPrivate(h,i) returns True exactly when the L-value
(h,i) indexes a private field, i, in the namespace at h.
The semantics of Lefthandside[[ I ]] remains the same, because it
does internal lookups, meaning it has the right to locate a private L-value.
(NOTE: Object languages that use public and private labels on object fields almost always check their uses with a compiler so that the the labels are not embedded with the fields in the run-time objects --- label checking is part of the compiler's "type checking". This section exists so to emphasize that dot indexing can never be used to reference a private field.)
Recall that the pronoun, this, denotes the active namespace, which
to this point coincided
with the notion of ``this object.'' Now that objects are compound
namespaces, the correspondence breaks down,
and we must alter the semantics of this to denote ``this object,''
a concept that differs from ''this namespace.''
Here is a simple use of this in a object-oriented language:
class C() : { var f = 0;
proc p(f) : this.f = f end };
var ob = new C();
ob.p(3)
Say that new C() generates a namespace whose handle is α and
holds 'f' = 0.
Then the call, ob.p(3), generates a namespace that holds the binding,
'f' = 3.
But the command, this.f = f, will assign 3 to the f inside
α.
Why does this happen? A typical object-oriented language decodes the call, ob.p(3) like this:
There is a simple semantics that explains the above steps. To employ it, we make one significant restriction to the programming language:
var c = new { var x = 1;
proc p(y): this.x = y end
};
var d = new { var x = 2;
var f = c.p // c.p alone cannot be a legal expression
};
d.f(99)
Procedure p means to update the x in c, but d.f(99) suggests
an update of x in d. (Should this bind
to c's handle or to d's handle?) We avoid the confusion by
prohibiting c.p as an expressible value.
(IMPORTANT: we can remove the restriction if we add a new form of closure, a partially evaluated call, to the machine model. Such a closure holds a procedure's code, its parameter names, some (not all!) of the arguments that bind to the parameter names, and a super-link. We won't use this closure here, but it is indeed doable and plays a significant role in implementations for Python and OCAML.)
Here are the revisions in the semantics of expressions, lefthandsides,
and procedure call:
===================================================
Expression[[ L ]] == let (han, id) = Lefthandside[[ L ]]
let val = heap[han][id]
if notHandleToClosure(val) : return val
(else erroneous)
Command[[ L ( E ) ]] == let (han,id) = Lefthandside[[ L ]]
let closure = heap[ heap[han][id] ]
let arg = Expression[[ E ]]
let han2 = allocateNS({'super' = closure['super'],
closure['param'] = arg,
'this' = han })
push(han2)
Command[[ closure['code'] ]]
pop()
Lefthandside[[ I ]] == ...as before...
Lefthandside[[ L . I ]] == ...as before...
Lefthandside[[ this ]] == if 'this' in heap[top()] :
return (top(), 'this')
else : return (actstack, 'this')
===================================================
The treatment of this as an extra procedure parameter is required for defining subclasses and method override, which come next.
Tennent's extension principles do not yield subclasses.
Indeed, subclassing is an operation on templates, independent
from abstracts, parameters, and blocks. In its most general form,
it is a ``template append'' operation:
T ::= { C } | L ( E ) | T1 + T2
This form is called a mix-in, and it would
be used like this:
class Point(a,b) : { var x = a; var y = b;
proc paint() : ...x...y...a...b... end;
proc display() : this.paint() end
};
class Color(c) : { var color = c;
proc paint(...) : super.paint(); ...color... end
};
class ColoredPoint(x,y,c) : Point(x,y) + Color(c);
var RGB = 999999;
var p = ColoredPoint(0,0,RGB)
We will undertake a more modest version of the append operation,
one that looks like that found in Java:
===================================================
D ::= ... | class I1 ( I2 ) : T | var I = E
E ::= ... | new T
T ::= { C } | L ( E ) | extends T with { C }
L ::= this | super | I | L . I
===================================================
Here is an example in the more modest syntax,
which exhibits features that we must address:
class Point(a,b) : { var x = a; var y = b;
proc paint() : ...x...y...a...b... end;
proc display() : this.paint() end
};
class ColoredPoint(m,n,c) : extends Point(m,n) with
{ var color = c;
proc paint(...) : super.paint(); ...color... end
};
var p1 = new Point(0,0);
var p2 = new ColoredPoint(9,88,777)
Our intuition tells us that object p1 will be modelled by two
namespaces, one holding bindings for a and b, and one holding
x, y, paint, and display.
Similarly, p2 will be a four-namespace object.
All of p2.paint, p2.display,
p2.color, p2.x., and p2.y are well-defined L-values, and
we must alter the semantics of L.I to ensure this is so.
And there is the notion of ``superobject'' (``superclass''), as used in super.paint() --- p2's paint method will call the paint method in the ``superobject part'' of p2.
Finally, there is virtual-method override at work: the call, p2.display(), invokes the method display in Point, whose call, this.paint(), activates the paint method in ColoredPoint (whereas, p1.display() activates paint in Point).
All these issues will be handled by a new linkage, implemented by a new field, 'superob', which links subclass-namespaces to superclass-namespaces.
The semantics is revised so that an object becomes a sequence of namespaces linked together by 'superob' links. To implement correctly this and virtual-method lookup, we restrict the semantics so that
In the above example, p2.display will compute to a well-defined L-value, of the form, (handleOf_p2, 'display'). But display is not stored within the namespace named by handleOf_p2. We must adjust the semantics of dereferencing to locate the closure for display in the super-namespace of the compound object named by the handleOf_p2.
We do this with a search along the chain of 'superob' links --- this is virtual-method lookup.
Here is the syntax of the relevant
fragment of the language, including a some phrases whose semantics remain the same:
===================================================
D ::= proc I1 ( I2 ) : C | class I1 ( I2 ) : T | var I = E
C ::= L = E | D | L ( E )
E ::= L | new T | ! E
T ::= { C } | L ( E ) | extends T with { C } | private D in T
L ::= this | I | L . I | super . I
===================================================
Here is the semantics. We add a lookup function
that translates an (object_handle, id) pair into the exact heap
L-value where id is saved in a (sub)namespace of the
object named by object_handle:
===================================================
virtualLookup((han, id), linkname) ==
// starting from handle han, searches for id in the namespaces
// along the linkage indicated by linkname and
// returns the exact L-value where id resides
let h = han
let found = False
while not found and h != nil :
if I in heap[h] : found = True
else : h = heap[h][linkname]
return (h, I)
Declaration[[.]] updates heap
[[ proc I1 ( I2 ) : C ]] == let active = top()
let han = allocateNS( {'param'= I2, 'code'= C,
'super'= active} )
lock(han)
heap[active][ I1 ] = han
[[ class I1 ( I2 ) : T ]] == let active = top()
let han = allocateNS( {'param'= I2, 'code'= T,
'super'= active} )
lock(han)
heap[active][ I1 ] = han
[[ var I = E ]] == heap[top()][I] = Expression[[ E ]]
Command[[.]] updates heap:
[[ D ]] == Declaration[[ D ]]
[[ L = E ]] == let (han, id) = virtualLookup(Lefthandside[[ L ]], 'superob')
heap[han][id] = Expression[[ E ]]
[[ L ( E ) ]] == let (object_handle, id) = Lefthandside[[ L ]]
let (han,id) = virtualLookup((object_handle, id), 'superob')
let closure = heap[ heap[han][id] ]
let arg = Expression[[ E ]]
let han2 = allocateNS({'super' = closure['super'],
closure['param'] = arg,
'this' = object_handle })
push(han2)
Command[[ closure['code'] ]]
pop()
Expression[[.]] updates heap returns Denotable:
[[ L ]] == let (han,id) = virtualLookup(Lefthandside[[ L ]], 'superob')
let val = heap[han][id]
if notHandleToClosure(val) : return val (else erroneous)
[[ new T ]] == return Template[[ T ]]
[[ ! E ]] == lock Expression[[ E ]]
Template[[.]] updates heap and returns Handle:
[[ { C } ]] == let newhandle = allocateNS({'super' = top(),
'superob' = nil})
push(newhandle)
Command[[ C ]]
pop()
return newhandle
[[ extends T with { C } ]] == let han1 = Template[[ T ]]
let han2 = allocateNS({'super' = top(),
'superob' = han1})
push(han2)
Command[[ C ]]
pop()
return han2
[[ private D in T ]] == let han = allocateNS({'super' = top()})
push(han)
Declaration[[ D ]]
lock han
let han2 = Template[[ T ]]
pop()
// make T's object own D's decls:
heap[han]['this'] = han2
return han2
[[ L ( E ) ]] == let (han,id) = virtualLookup(Lefthandside[[ L ]], 'superob')
let closure = heap[ heap[han][id] ]
let arg = Expression[[ E ]]
let han = allocateNS({'super' = closure['super'],
closure['param'] = arg})
push(han)
let han2 = Template[[ closure['code'] ]]
pop()
return han2
Lefthandside[[.]] returns LValue:
// the LValue has form, (object_handle, field), where object_handle
// is the entry handle into the compound namespace where field is located
[[ I ]] == virtualLookup((top(), I), 'super')
[[ L . I ]] == let (han,id) = virtualLookup(Lefthandside[[ L ]], 'superob')
let han2 = heap[han][id]
return (han2, I)
[[ this ]] == if 'this' in heap[top()] :
return (top(), 'this')
else :
return (actstack, 'this')
[[ super . I ]] == if 'this' in heap[top()] :
han = heap[top()]['this']['superob']
else : han = heap[top()]['superob']
return (han, I)
===================================================
A DSL uses concepts familiar to people who work in a specialized problem domain. For example, say that you must install an alarm system in an office building. A DSL for sensor-alarm networks would discuss
A top-down DSL has a mix of assets and drawbacks:
A bottom-up DSL ``extends'' a general-purpose language, the host language, with a library of data structures and operations specific to the problem domain. GUI-building languages are bottom-up DSLs, e.g., Swing (in Java), Tkinter (in Python), and Glade (in C).
Experienced programmers naturally become bottom-up DSL designers, because they develop libraries they use repeatedly. Eventually, their programs consist mostly of their library components and a little ``glue code'':
A bottom-up DSL has its strengths and weaknesses also:
The runtime model you design must be natural and understandable to the domain's users. In particular, choose carefully the language's command/control structures. (E.g., physicists might not enjoy writing while-loops --- recurrence equations would be better.)
Refine the libraries, model, and glue code until the library becomes ``more important'' to problem solving than the host language itself.
Fowler, M. Language Workbenches: The Killer-App for Domain Specific Languages? WWW.MARTINFOWLER.COM, 2005. http://www.issi.uned.es/doctorado/generative/Bibliografia/Fowler.pdf.
Nielson, H.-R, and Nielson, F. Semantics with Applications. Springer, 2007.
Schmidt, D.A. On the Need for a Popular Formal Semantics. Proc. ACM Conference on Strategic Directions in Computing Research, Boston. ACM SIGPLAN Notices 32-1 (1997) 115-116. http://people.cis.ksu.edu/~schmidt/papers/boston3.ps.gz
Schmidt, D.A. Programming Language Paradigms. Course Notes, Kansas State University, 2010. http://www.cis.ksu.edu/~schmidt/505f10.
Stoy, J. Denotational Semantics: The Scott-Strachey Approach to Programming Language Theory. MIT Press, 1974.
Tennent, R.D. Principles of Programming Languages. Prentice-Hall, 1981.